Binary Vector: bvector since v0.3.0
The bvector type is a binary vector type in pgvecto.rs. It represents a binary vector, which is a vector where each component can take on two possible values, typically 0 and 1.
Here's an example of creating a table with a bvector column and inserting values:
CREATE TABLE items (
id bigserial PRIMARY KEY,
embedding bvector(3) NOT NULL
);
INSERT INTO items (embedding) VALUES ('[1,0,1]'), ('[0,1,0]');Index can be created on bvector type as well.
CREATE INDEX your_index_name ON items USING vectors (embedding bvector_l2_ops);
SELECT * FROM items ORDER BY embedding <-> '[1,0,1]' LIMIT 5;We support three operators to calculate the distance between two bvector values.
<->(bvector_l2_ops): squared Euclidean distance, defined as. The Hamming distance is equivalent to the squared Euclidean distance for binary vectors. <#>(bvector_dot_ops): negative dot product, defined as. <=>(bvector_cos_ops): cosine distance, defined as. <~>(bvector_jaccard_ops): Jaccard distance, defined as.
There is also a function binarize to build bvector from vector. It truncates vector elements to integers of 0 or 1.
-- binarize(source: vector) -> bvector
SELECT binarize('[-2, -1, 0, 1, 2]'::vector);
-- [0, 0, 0, 1, 1]Performance
The bvector type is optimized for storage and performance. It uses a bit-packed representation to store the binary vector. The distance calculation is also optimized for binary vectors.
Here are some performance benchmarks for the bvector type. We use the dbpedia-entities-openai3-text-embedding-3-large-3072-1M dataset for the benchmark. The VM is n2-standard-8 (8 vCPUs, 32 GB memory) on Google Cloud.
We upsert 1M binary vectors into the table and then run a KNN query for each embedding. It only takes about 600MB memory to index 1M binary vectors, while the vector type takes about 18GB memory to index the same number of vectors.
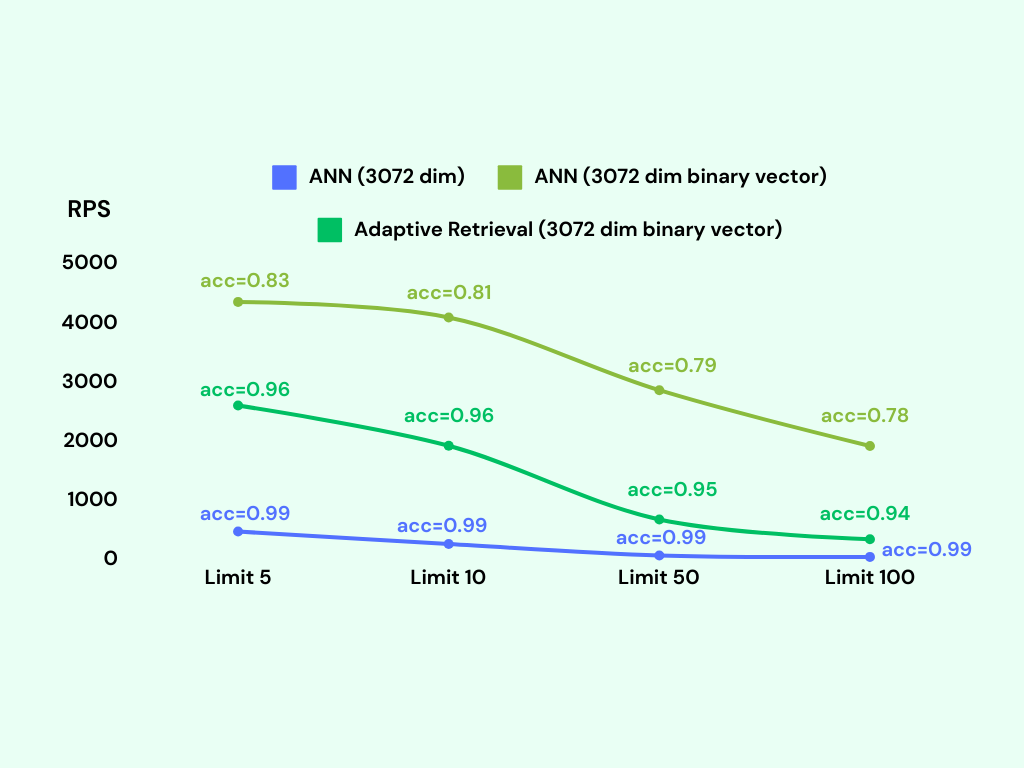
We can see that the bvector's accuracy is not as good as the vector type, but it exceeds 95% if we adopt adaptive retrieval.